Event Driven Architecture
EDA – All you need to know
Real-world systems often rely on distributed software systems. That’s why it is crucial to establish the interconnectivity and interoperability between these systems. It’s now getting more common for system designs to be built on event-driven architecture. Why? Because this is the way to enable efficient, real-time communication between different components without them being aware of one another.
In this post, we’re going to talk about event-driven architecture (EDA) and its most commonly used messaging pattern: publish/subscribe (pub/sub). The Data Distributions Service is an implementation of EDA because it is based on a publish-subscribe communication model.
I’ll explain how things work within event-driven systems, what differentiates them from the so-called traditional methods, and when they are a good fit for your system.
What is EDA
Event-driven architecture (EDA) has suddenly become a hot topic among system architects. There was an initial wave of interest in EDA when message-oriented middleware (MOM), including publish-and-subscribe (pub/sub) messaging systems, emerged in the 1990s. But most systems architecture continued to use synchronous communication. It used to be Service-oriented architecture (SOA), nowadays it is microservices with APIs.
Synchronous communication works as follows. A client application makes a call and waits for a server to respond with the requested content.
Event-driven architecture is a shift from a tightly-coupled synchronous communication type, where a request/response communication model is used, to a loosely-coupled asynchronous communication type where point-to-point and publish-subscribe messaging is used.
What are the differences between an Event-driven system and a Request or Command driven system?
When comparing an Event-driven system and a Request or Command driven system you can think of it this way.
In Request/command-driven systems you ask questions from others or tell others what to do, and you wait for some response. These lead to tight coupling and in a large system can lead to problems with availability, because the failure of one part can cause the failure of the whole system. It is also more difficult to make changes in such a tightly coupled system.
- An example of a request-driven system could be: You, discovery server, give me all services I can communicate with. You can treat data in such a system as Data at Rest (because data are stored somewhere and can be queried).
- An example of a command-driven system could be: “You, brake control system, I command, stop the car!”
In Event-driven systems you tell others what you did or ask for state change and others determine what they do. You do not need to wait for any response.
- For example, I need the state of the car to be stopped and I do not care who accomplish it. You can treat data in such a system as Data in Motion (because they are sent as soon as they are available).
- Imagine, for example, a patient in a hospital who is monitored by a medical machine. If a certain threshold is exceeded for monitored variables, it is necessary to react immediately. For example, by automatic application of sedatives and informing the medical staff. In this case, using a request-response approach would not be effective. In 99% of cases, nothing may happen, but if something does happen, I need to know right away and react immediately, not 5 seconds later.
Publish-subscribe in nutshell
Event-driven architecture can use a publish-subscribe model of communication (used e.g. by DDS) or an event streaming model of communication (used e.g. by Apache Kafka). Let’s focus here on what a Publish-subscribe model of communication is.
Publish-subscribe is a one-to-many model of communication. Publish-subscribe applications are typically distributed applications with endpoint nodes that communicate with each other by sending (publishing) data and receiving (subscribing) data anonymously. Usually, the only property a publisher needs to communicate with a subscriber is the name and definition of the data. The publisher does not need any information about the subscribers, and vice versa – they are decoupled. As long as the interested applications know what data is being communicated, a publish-subscribe infrastructure is capable of delivering that data to the appropriate nodes— without applications having to set up individual connections. Publishers are responsible for gathering the appropriate data and sending it out to all registered subscribers. Subscribers are responsible for receiving data. Communication between publishers and subscribers is asynchronous.
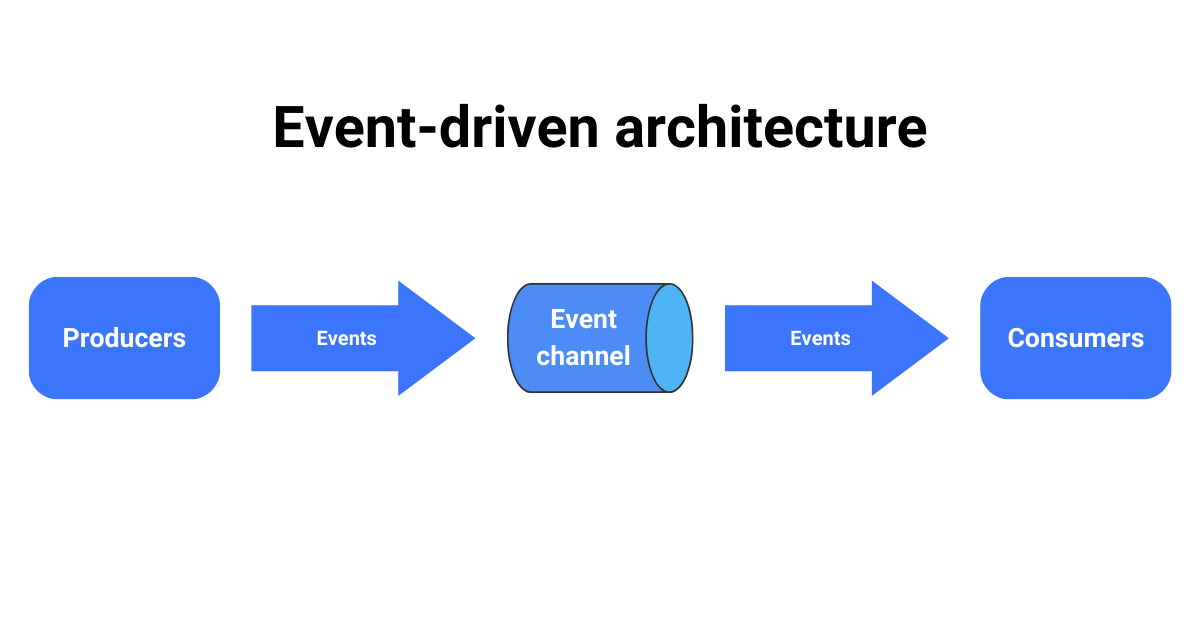
Basic building blocks of EDA
An event-driven architecture consists of event producers, like sensors or applications, that generate a stream of events, on one side and event consumers that listen for the events and process and react to them on the other side.
The Event Channel is used for communication between event producers and event consumers.
- This channel can use a point-to-point communication model, where the queues are used so only one from many consumers consumes each message (this is how e.g. ActiveMQ, RabbitMQ works).
- It can use the Publish-subscribe communication model where topics are used so every subscribed application obtains the message and can process it differently (this is how e.g. MQTT, DDS works)
- Or it can use an event stream. Events are written to a log. Applications can connect to the stream and read different parts of the stream – as allowed by Apache Kafka and NATS Streaming for example.
Benefits
So, why would we use EDA? There are several benefits when using EDA especially when using the publish-subscribe communication model.
The benefits are scalability, loose coupling, fault tolerance and asynchronous communication. Let’s go through them one by one.
- Scalability: EDAs allow for great horizontal scalability as one event may trigger responses from multiple applications with different needs and provide different results.
- Loose coupling: Producers and consumers are unaware of each other. There is either an intermediary that receives events from producers and sends them to interested consumers or there is a Discovery phase among applications so after the producers and consumers discover each other they can then communicate peer-to-peer. This allows for loose coupling of applications and facilitates their modifying, testing, and deployment. And unlike point-to-point application integrations, applications can be easily added to or removed from a system. The architecture can therefore evolve.
- Asynchronous communication: Events are sent asynchronously, that means that events are sent by producers as they happen and consumers can consume or process them right away (or later if the consumer is not available, but it doesn’t affect or block a producer). This leads to better responsiveness and performance of the system.
- Fault tolerance: Loose coupling goes hand in hand with fault tolerance. The failure of one application has no effect on other applications and the system continues to work, at least partially. This leads to better resilience of the system.
Disadvantages
There are several considerations you should take into account when you are dealing with EDA. It is mainly because of EDA’s distributed and asynchronous nature. The disadvantages of EDA system are the following.
- In general, it is increased complexity, because you have more parts that consists of EDA system. Hence there is less control over the processing flows and it is more difficult to test and debug the system. That’s why it’s very important to invest in an observability infrastructure so that you have monitoring, logging and tracing features in the system to make sure everything is running smoothly.
- Only an Eventual consistency applies to data or system state consistency. It’s because it takes some time to propagate the data or state change within the whole system.
- It’s difficult to implement transactions that span several applications.
- There is a potential for duplicate processing and out-of-order processing. This is because the network is unreliable and you can run each consumer type in multiple instances (for resiliency and scalability). This can cause a problem if events must need to be processed in order (within a consumer type), or if the processing logic is not idempotent.
When to use this architecture
You should consider using EDA in the following use cases.
- Your system consist of Multiple subsystems that need to operate in response to the same event.
- If you need to continuously monitor the resource state and receive notifications in real-time about any changes and updates. That means you need a very responsive system.
- You need Complex event processing, such as pattern matching or aggregation over time windows.
- You deal with a high volume and high velocity of data (e.g. IoT data).
- You want to improve your existing systems and make them more scalable and responsive.
In such cases you should consider creating a system based on EDA.
Communication technologies
What are communication technologies that enable the creation of EDA?
There are a lot of publish-subscribe communication protocols and technologies that can facilitate the creation of EDA.
You can choose from:
- Communication protocols: AMQP, MQTT.
- Communication Middlewares (on premise solution): ActiveMQ, RabbitMQ, Apache Kafka, DDS, NATS, Zenoh.
- Cloud services: Companies like Amazon, Microsoft, Google supports different technologies like:
- Message Queue:
- Amazon SQS – Message Queue Service by AWS
- Azure Service Bus – Queue Service by Microsoft Azure
- Google Cloud Task – Queue Service by by Google Cloud Platform
- Publish Subscribe:
- Amazon SNS – Pub/Sub Service by AWS
- Azure Service Bus – Pub/Sub Service by Microsoft Azure
- Google Cloud Pub/Sub – Pub/Sub service by Google Cloud Platform
- Event Streaming:
- Amazon Kinesis – Pub/Sub Service by AWS
- Azure Event Hubs – Pub/Sub Service by Microsoft Azure
- Google Cloud Pub/Sub – Pub/Sub service by Google Cloud Platform
- Message Queue:
EDA or not EDA
EDA isn’t a universal solution that fits all scenarios without exception. If your systems are simple and unlikely to scale up, and you do not need real-time responsive system, there’s no need to overcomplicating things. Request/response models are still relevant for variety of cases. In any case, first decide what architecture you need for your system and its parts and only then choose the appropriate technology. Not the other way around. In fact, technology can simplify the design, implementation and maintenance of your system, but if you choose the wrong architecture, you will likely have to redesign your system, which is not a pleasant experience.
What strategies can be employed to handle event versioning and schema evolution in dynamic environments? and given the asynchronous nature of EDA, what tools and practices are effective for monitoring and debugging event flows?